serhii.net
In the middle of the desert you can say anything you want
-
Day 1859 (02 Feb 2024)
CBT Story proofreading for Masterarbeit
Related: 240202-1312 Human baselines creation for Masterarbeit
Problem: I have generated stories, I want to proofread them.
Label-studio is better than the previous Google Sheets way, but I’m not yet sure whether the overhead is worth it.
I’ll keep the thing below here just in case for later.
<View> <View style="display: grid; grid-template: auto/1fr 1fr; column-gap: 1em"> <Header value="Original generated story" /> <Header value="Proofread and spell-checked story" /> <Text name="generated_story" value="$generated_story" /> <TextArea name="fixed_story" toName="generated_story" transcription="true" showSubmitButton="true" maxSubmissions="1" editable="true" required="true" value="$generated_story" rows="40"/> </View> <TextArea name="comments" toName="generated_story" editable="true" placeholder="Comments" /> </View> <!-- { "data": { "generated_story": "Колись давним-давно, у маленькому селі, що лежало на краю великого лісу, жила сильна Кішка. Вона була відома своєю мудрістю та справедливістю серед усіх мешканців лісу. Її сусідами були Лисиця та Заєць, які жили поруч у своїх затишних домівках.\n\nОдного дня до села прийшли два вовки, які шукали нове місце для життя. Вони були великі та могутні, але їхній характер був жорстоким і хитрим. Вовки вирішили, що дім Лисиці стане ідеальним місцем для їхнього нового житла, і почали примушувати Лисицю покинути свій дім.\n\nЛисиця, зневірена та перелякана, звернулася до Кішки з проханням допомогти вирішити цю справу. Кішка, знаючи про свою відповідальність перед сусідами, погодилася допомогти.\n\nКішка зустрілася з вовками і спробувала переконати їх залишити Лисицю у спокої. Вона говорила про важливість миру та гармонії у лісовій громаді, але вовки лише сміялися з її слів. Вони не бажали слухати розумні доводи, адже їхнє бажання влади було ненаситним.\n\nЗаєць, який був свідком цієї розмови, запропонував Кішці влаштувати змагання між вовками та Лисицею, де переможець отримає дім. Кішка, хоч і сумнівалася в цій ідеї, вирішила спробувати, адже інших варіантів не було.\n\nЗмагання полягало в тому, щоб знайти найрідкіснішу квітку в лісі. Лисиця, знаючи ліс як свої п'ять пальців, швидко знайшла квітку. Вовки ж, не зважаючи на правила, вирішили просто вкрасти квітку у Лисиці.\n\nКоли Кішка дізналася про їхню підступність, вона з гнівом заявила, що вовки програли змагання через свою нечесність." } } -->Unsolved issues:
- backups of the docker container
- its main data directory contains everything it seems
- automate copies?
Possible flow:
- Story generator fills a CSV with stories
- Converter takes the CSV and generates a Label-studio dataset,
- It gets uploaded to LS, people correct the dataset, gets exported from LS
- Converter takes LS exported data and creates a spreadsheet out of it again?…
Can I simplify it?
- Use CSV w/ same parameters for both input and output, then no conversion needed
- This works! CSV in, CSV out
- column names are not
[to/from]Name=as the export dialog says, but thenameof the respective fields
- Bonus points for directly pointing it to a google spreadsheet?
- everything here is overkill: Label Studio Documentation — Cloud and External Storage Integration
- manual it is then I think
New layout
<View> <View style="display: grid; grid-template: auto/1fr 1fr; column-gap: 1em"> <Header value="Original generated story" /> <Header value="Proofread and spell-checked story" /> <Text name="generated_story" value="$generated_story" /> <TextArea name="fixed_story" toName="generated_story" transcription="true" showSubmitButton="true" maxSubmissions="1" editable="true" required="true" value="$generated_story" rows="40"/> </View> <TextArea name="comments" toName="generated_story" editable="true" placeholder="Comments" /> <Choices name="status" toName="generated_story" choice="single-radio" showInLine="true"> <Choice value="todo" html="TODO (не закінчено)" selected="true" hotkey="2"/> <Choice value="done" html="done" hotkey="1"/> </Choices> <Choices name="others" toName="generated_story" choice="multiple" showInLine="true"> <Choice value="notable" html="notable (ум. мова ітп.)"/> <Choice value="few_characters" html="коротка / мало головних героїв"/> <Choice value="hopeless" html="nonsense/hopeless"/> </Choices> </View> <!-- { "data": { "generated_story": "Колись давним-давно, у маленькому селі, що лежало на краю великого лісу, жила сильна Кішка. Вона була відома своєю мудрістю та справедливістю серед усіх мешканців лісу. Її сусідами були Лисиця та Заєць, які жили поруч у своїх затишних домівках.\n\nОдного дня до села прийшли два вовки, які шукали нове місце для життя. Вони були великі та могутні, але їхній характер був жорстоким і хитрим. Вовки вирішили, що дім Лисиці стане ідеальним місцем для їхнього нового житла, і почали примушувати Лисицю покинути свій дім.\n\nЛисиця, зневірена та перелякана, звернулася до Кішки з проханням допомогти вирішити цю справу. Кішка, знаючи про свою відповідальність перед сусідами, погодилася допомогти.\n\nКішка зустрілася з вовками і спробувала переконати їх залишити Лисицю у спокої. Вона говорила про важливість миру та гармонії у лісовій громаді, але вовки лише сміялися з її слів. Вони не бажали слухати розумні доводи, адже їхнє бажання влади було ненаситним.\n\nЗаєць, який був свідком цієї розмови, запропонував Кішці влаштувати змагання між вовками та Лисицею, де переможець отримає дім. Кішка, хоч і сумнівалася в цій ідеї, вирішила спробувати, адже інших варіантів не було.\n\nЗмагання полягало в тому, щоб знайти найрідкіснішу квітку в лісі. Лисиця, знаючи ліс як свої п'ять пальців, швидко знайшла квітку. Вовки ж, не зважаючи на правила, вирішили просто вкрасти квітку у Лисиці.\n\nКоли Кішка дізналася про їхню підступність, вона з гнівом заявила, що вовки програли змагання через свою нечесність." } } -->Todo fascinating how much яскравих animals are found in the stories. Guess who was wrong about saying “bright” in the templates
Human baselines creation for Masterarbeit
Goals/reqs:
- sth easy so I can send a link to people, ideally w/o registration, and they can immediately label stuff
- CBT & some lmentry-static: model as document classification
- needs to be able to show the tasks in pretty multiline formatted format
- ideally python, or at least docker
Shortlist of my options:
- https://github.com/HumanSignal/label-studio
- https://github.com/davidjurgens/potato
- https://github.com/alexandre01/UltimateLabeling
label-studio
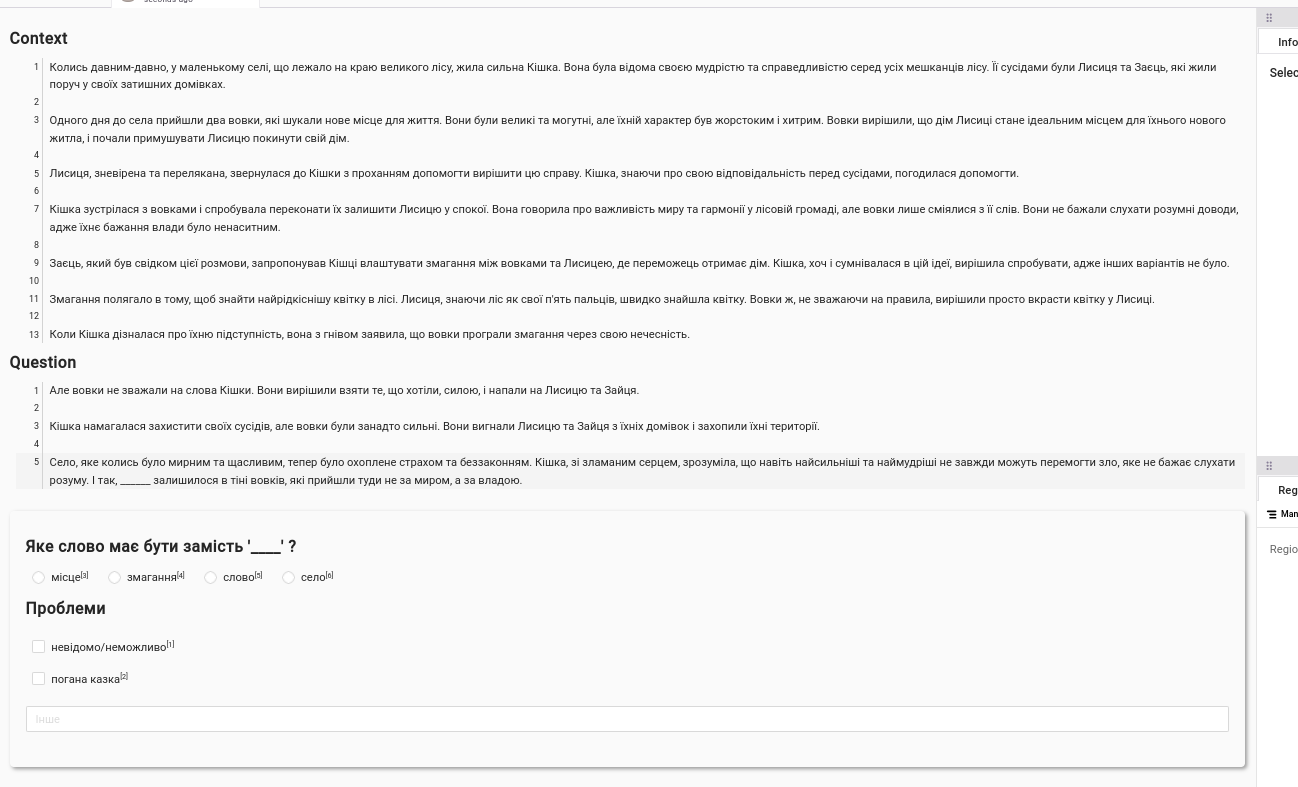
<View> <Header value="Context"/> <Text name="text_context" value="$context"/> <Header value="Question"/> <Text name="text_question" value="$question"/> <Text name="options" value="$options"/> <View style="box-shadow: 2px 2px 5px #999; padding: 20px; margin-top: 2em; border-radius: 5px;"> <Header value="Яке слово має бути замість '____' ?"/> <Choices name="answers" toName="text_question" choice="single" showInLine="true"> <Choice value="A" html="<b>A</b>"/><Choice value="B" html="<b>B</b>"/><Choice value="C" html="<b>C</b>"/> <Choice value="D" html="<b>D</b>"/> </Choices> <Choices name="answers2" toName="text_question" choice="single" showInLine="false"> <Choice value="unknown" html="невідомо/неможливо"/> <Choice value="bad_story" html="погана казка"/> </Choices> </View> </View>Problem: options are shown like a list of str, because it doesn’t parse the csv column as a list, but as a str.
I’ll try to get around this by using JSON as input
.. and I can’t, it ignores whatever json i provide to it.
Worst case scenario I’ll generate a string with all options as STR to show it.
- ah, it’s still STR
I think I have it!
<View> <Header value="Context"/> <Text name="text_context" value="$context"/> <Header value="Question"/> <Text name="text_question" value="$question" /> <Text name="options" value="$options"/> <View style="box-shadow: 2px 2px 5px #999; padding: 20px; margin-top: 2em; border-radius: 5px;"> <Header value="Яке слово має бути замість '____' ?"/> <Choices name="answers" toName="text_question" choice="single-radio" showInLine="true" value="$options_forls"> </Choices> <Header value="Проблеми"/> <Choices name="answers2" toName="text_question" choice="multiple" showInLine="false"> <Choice value="unknown" html="невідомо/неможливо"/> <Choice value="bad_story" html="погана казка"/> </Choices> <TextArea name="comments" toName="text_question" editable="true" placeholder="Інше" /> </View> </View> <!-- { "data": { "context": "Колись давним-давно, у маленькому селі, що лежало на краю великого лісу, жила сильна Кішка. Вона була відома своєю мудрістю та справедливістю серед усіх мешканців лісу. Її сусідами були Лисиця та Заєць, які жили поруч у своїх затишних домівках.\n\nОдного дня до села прийшли два вовки, які шукали нове місце для життя. Вони були великі та могутні, але їхній характер був жорстоким і хитрим. Вовки вирішили, що дім Лисиці стане ідеальним місцем для їхнього нового житла, і почали примушувати Лисицю покинути свій дім.\n\nЛисиця, зневірена та перелякана, звернулася до Кішки з проханням допомогти вирішити цю справу. Кішка, знаючи про свою відповідальність перед сусідами, погодилася допомогти.\n\nКішка зустрілася з вовками і спробувала переконати їх залишити Лисицю у спокої. Вона говорила про важливість миру та гармонії у лісовій громаді, але вовки лише сміялися з її слів. Вони не бажали слухати розумні доводи, адже їхнє бажання влади було ненаситним.\n\nЗаєць, який був свідком цієї розмови, запропонував Кішці влаштувати змагання між вовками та Лисицею, де переможець отримає дім. Кішка, хоч і сумнівалася в цій ідеї, вирішила спробувати, адже інших варіантів не було.\n\nЗмагання полягало в тому, щоб знайти найрідкіснішу квітку в лісі. Лисиця, знаючи ліс як свої п'ять пальців, швидко знайшла квітку. Вовки ж, не зважаючи на правила, вирішили просто вкрасти квітку у Лисиці.\n\nКоли Кішка дізналася про їхню підступність, вона з гнівом заявила, що вовки програли змагання через свою нечесність.", "question": "Але вовки не зважали на ______ Кішки. Вони вирішили взяти те, що хотіли, силою, і напали на Лисицю та Зайця.\n\nКішка намагалася захистити своїх сусідів, але вовки були занадто сильні. Вони вигнали Лисицю та Зайця з їхніх домівок і захопили їхні території.\n\nСело, яке колись було мирним та щасливим, тепер було охоплене страхом та беззаконням. Кішка, зі зламаним серцем, зрозуміла, що навіть найсильніші та наймудріші не завжди можуть перемогти зло, яке не бажає слухати розуму. І так, село залишилося в тіні вовків, які прийшли туди не за миром, а за владою.", "options": [ "село", "слова", "змагання", "місця" ], "answer": "слова", "storyId": 10, "additionalMetadata_repl_type": "COMMON_NOUN", "additionalMetadata_context_sents_n": 17, "additionalMetadata_context_sents_tokens": 278, "additionalMetadata_question_sents_tokens": 557, "additionalMetadata_question_sents_share": 0.3, "additionalMetadata_num_repl_opts_from_text": 4, "additionalMetadata_label": 1, "options_forls": [ { "value": "село", "html": "село" }, { "value": "слова", "html": "слова" }, { "value": "змагання", "html": "змагання" }, { "value": "місця", "html": "місця" } ], "options_show_str": "А: село\nБ: слова\nВ: змагання\nГ: місця" } } -->(If I’ll need example again, the LLM comparison example layout is helpful, esp. how to format the data dict during layout creation for it to actually work instead of quietly failing)
I like this. I think I’ll use label-studio for my own filtering of bad stories/tasks as well maybe?
Ones I’ll manually check.
- Виберіть правильну відповідь для кожного завдання - Якщо щось не ОК, є дві галочки з варіантами: - невідомо/неможливо: якщо в казці немає інформації для відповіді - погана казка: якщо казка повний тотальний нонсенс і її варто виключити повністю - Поле "інше" там про всяк випадок, і виключно якщо є бажання щось додавати. Наприклад, якщо є граматичні помилки чи щось таке. Клавіши: - 1..n для вибору правильного варіанту - 9 для "невідомо/неможливо", 0 для "погана казка" - Ctrl+Enter для "зберегти і далі" - Ctrl+Space для "пропустити" ДЯКУЮ ВАМ!Default dir locations:
~/.local/share/label-studio
> poetry run label-studio init --data-dir=../../data/human_baselines/CBT/ --username=me --password=xxx- Settings
- Random sampling to attempt to get around the fact that the stories are the same
Gotchas & bits
- commas at the end of json should not be present for the last element
- if you have a template referencing some variables, if you upload a new dataset w/o these variables it’ll fail during import
- CSV export doesn’t overwrite already existing columns it seems
- the
</>symbol is ‘show task source’ that shows both the raw input as well as the annotations, same format as export basically - multiple hotkeys work for me but not for everyone: Setting multiple Hotkeys per Component breaks the UI permanently (in that browser window) · Issue #4183 · HumanSignal/label-studio
Instructions for editing stories
Put them here: 240206-1619 CBT Story correction instructions
- backups of the docker container
-
Day 1858 (01 Feb 2024)
Formatting floats as strings inside a list comprehension
Never thought of this, but I can use f-strings inside list comprehensions inside f-strings:
logger.info(f"Stories split into {'/'.join(f'{x:.2f}' for x in actual_split_sizes)}")(Not that it’s necessarily a good idea to.)
pytest approx as almostequal
Pytest has pytest.approx() that does what unittest’s
almostEqual()does for python floating point arithmetic quirks:from pytest import approx def test_splitting(): ns = [ [0.4], [0.4, 0.5], ] expected = [ [0.4, 0.6], [0.4, 0.5, 0.1], ] for i,n in enumerate(ns): assert _find_split_sizes(n)==approx(expected[i])(Quirks being basically this)
18:22:52 ~/uuni/master/code/ua_cbt/src/ 0 > python3 Python 3.8.10 (default, Nov 22 2023, 10:22:35) [GCC 9.4.0] on linux Type "help", "copyright", "credits" or "license" for more information. >>> 0.1+0.2 0.30000000000000004
-
Day 1857 (31 Jan 2024)
Connecting to a Rancher pod with kubectl terminal
- Put new config in
~/.kube/configif needed. kubectl describe nodesas a sanity-check that it works
To run stuff
kubectl exec -it pod-name -n namespace -- bashThe namespace bit is critical, otherwise one may get errors like
kubectl exec [POD] [COMMAND] is DEPRECATED and will be removed in a future version. Use kubectl exec [POD] -- [COMMAND] instead. Error from server (Forbidden): pods "podname" is forbidden: User "user" cannot get resource "pods" in API group "" in the namespace "default"
If
screenCLI is bad, it’s because it’ssh, runbashand everything will work.screen -R screenname bash
To run a pod w/ CLI:
kubectl apply -f pod.yaml
To view logs:
kubectl logs podname -n namespace
To copy files:
kubectl cp [LOCAL_FILE_PATH] [NAMESPACE]/[POD_NAME]:[REMOTE_FILE_PATH] kubectl cp [LOCAL_FILE_PATH] [NAMESPACE]/[POD_NAME]:[REMOTE_FILE_PATH]
Setup for Dockerfiles where you can look around before running
I run a command w/ ARGs as CMD inside a Dockerfile.
Howto
I’d like to
docker run -e "WHAT=ever" image bashto drop into bash to look around and maybe change the main command, for this I’d need to generate somecommand.sh, but I can’t, because Docker ARGs are available at buildtime but not runtime. (And I don’t want to use env variables because I want tocat mycommand.shto copypaste what would run instead of looking at the values of environment variables.)I came up with this setup:
FROM nvidia/cuda:11.6.2-runtime-ubuntu20.04 ARG DEVICE ARG HF_MODEL_NAME ARG LIMIT ARG TASKS=truthfulqa # .... COPY resources/entrypoint.sh /entrypoint.sh RUN chmod +x /entrypoint.sh ENTRYPOINT ["/entrypoint.sh"] CMD ["/command.sh"]entrypoint.sh:#!/bin/bash # echo "I am entrypoint" echo "python3 -m lm_eval --model hf --model_args pretrained=${HF_MODEL_NAME} --limit $LIMIT --write_out --log_samples --output_path /tmp/Output --tasks $TASKS --device $DEVICE --verbosity DEBUG --include_path /resources --show_config" > /command.sh echo "echo I am command.sh" >> /command.sh chmod +x /command.sh if [ $# -eq 0 ]; then # If we have no args to the entrypoint, run the main command /command.sh else # If we do, assume it's a program and execute it echo "exec-ing $@" exec "$@" fiThen, this command will run the entrypoint.sh that creates command.sh and then runs it:
docker run --rm -it -e "DEVICE=cpu" -e "HF_MODEL_NAME=TinyLlama/TinyLlama-1.1B-Chat-v1.0" -e "LIMIT=1" -e "TASKS=openbookqa-test" me/lm-eval:0.0.17And this one runs the entrypoint that creates command.sh and then runs
bash, dropping me into a shell where I cancat /command.shetc.:docker run --rm -it -e "DEVICE=cpu" -e "HF_MODEL_NAME=TinyLlama/TinyLlama-1.1B-Chat-v1.0" -e "LIMIT=1" -e "TASKS=openbookqa-test" me/lm-eval:0.0.17 bashRefs
Docker ENTRYPOINT and CMD : Differences & Examples:
- ENTRYPOINT is the program that gets executed when the container starts,
/bin/shby default - CMD are the arguments to that program.
The usual
CMD whateverat the end of Dockerfiles then means/bin/sh whatever.Here we use that to our advantage to decide what to run, while guaranteeing that the command.sh gets created always.
CMDcan be overridden by appending to thedocker runcommand, likedocker run ... image bashabove.ENTRYPOINTcan be overridden with the--entrypointargument todocker run.
Rancher/k8s pods
I often want to do something similar for a Docker image running on Rancher. For this I usually use sth like this (230311-1215 Rancher and kubernetes basics):
spec: containers: - name: project-lm-eval-container-name-2 image: me/lm-eval:0.0.17 command: - /bin/sh - -c - while true; do echo $(date) >> /tmp/out; sleep 1; doneDefine a Command and Arguments for a Container | Kubernetes mentions something that can be a better way.
#!/bin/bash echo "python3 -m lm_eval --model hf --model_args pretrained=${HF_MODEL_NAME} --limit $LIMIT --write_out --log_samples --output_path /tmp/Output --tasks $TASKS --device $DEVICE --verbosity DEBUG --include_path /resources --show_config" > /command.sh echo "echo I am command.sh" >> /command.sh chmod +x /command.sh if [ $# -eq 0 ]; then # If we have no args to the entrypoint, run the main command /command.sh elif [ "$1" = "sleep" ]; then while true; do echo sleeping on $(date) sleep 10 done else # If we have any other arg, assume it's a command and execute it exec "$@" fiWhen it has
sleepas an argument, it’ll sleep, the rest is unchanged.Pod
apiVersion: v1 kind: Pod metadata: name: xx namespace: xx spec: containers: - name: project-lm-eval-container-name-2 image: me/lm-eval:0.0.17 # If BE_INTERACTIVE == "sleep", ./entrypoint will be an infinite loop # (if it's empty, it'll run the thing as usual) # (if it's anything else, it will run that command, e.g. bash) command: - /entrypoint.sh args: ["$(BE_INTERACTIVE)"] env: # all of them, plus: - name: BE_INTERACTIVE valueFrom: configMapKeyRef: name: lm-eval-cmap key: BE_INTERACTIVEA bit ugly, sth like RUN_MODE would be better, but now:
- BE_INTERACTIVE is in a config map, becomes an env variable
- If set to
sleep, the pod will run the infinite loop, then I can “Execute shell” andecho /command.shetc.!
Prettier multiline
This was hard to get right with newlines replacements etc., but this can write command.sh in nice multiline format:
cat > /command.sh <<EOF python3 -m lm_eval \\ --model hf \\ --model_args pretrained=$HF_MODEL_NAME \\ --limit $LIMIT \\ --write_out \\ --log_samples \\ --output_path /tmp/Output \\ --tasks $TASKS \\ --device $DEVICE \\ --verbosity DEBUG \\ --include_path /resources \\ --show_config EOFNo quotes around ‘EOF’, double backslashes, no slashes before $ (with them the replacement will happen during runtime, not creation.)
Sleep after run
Last update on this:
run_then_sleepexecutes th the command immediately then sleeps, and I can connect to the container. Nice for Rancher and co that don’t create the container immediately, and I have to wait for it to be able to start stuff.#!/bin/bash cat > /command.sh <<EOF python3 -m lm_eval \\ --model hf \\ --model_args pretrained=$HF_MODEL_NAME \\ --limit $LIMIT \\ --write_out \\ --log_samples \\ --output_path /tmp/Output \\ --tasks $TASKS \\ --device $DEVICE \\ --verbosity DEBUG \\ --include_path /resources \\ --show_config EOF echo "echo I am command.sh" >> /command.sh chmod +x /command.sh if [ $# -eq 0 ]; then # If we have no args to the entrypoint, run the main command /command.sh elif [ "$1" = "sleep" ]; then while true; do echo sleeping sleep 10 done elif [ "$1" = "run_then_sleep" ]; then /command.sh while true; do echo sleeping after run sleep 100 done else # If we have any other arg, assume it's a command and execute it exec "$@" fi
- Put new config in
-
Day 1856 (30 Jan 2024)
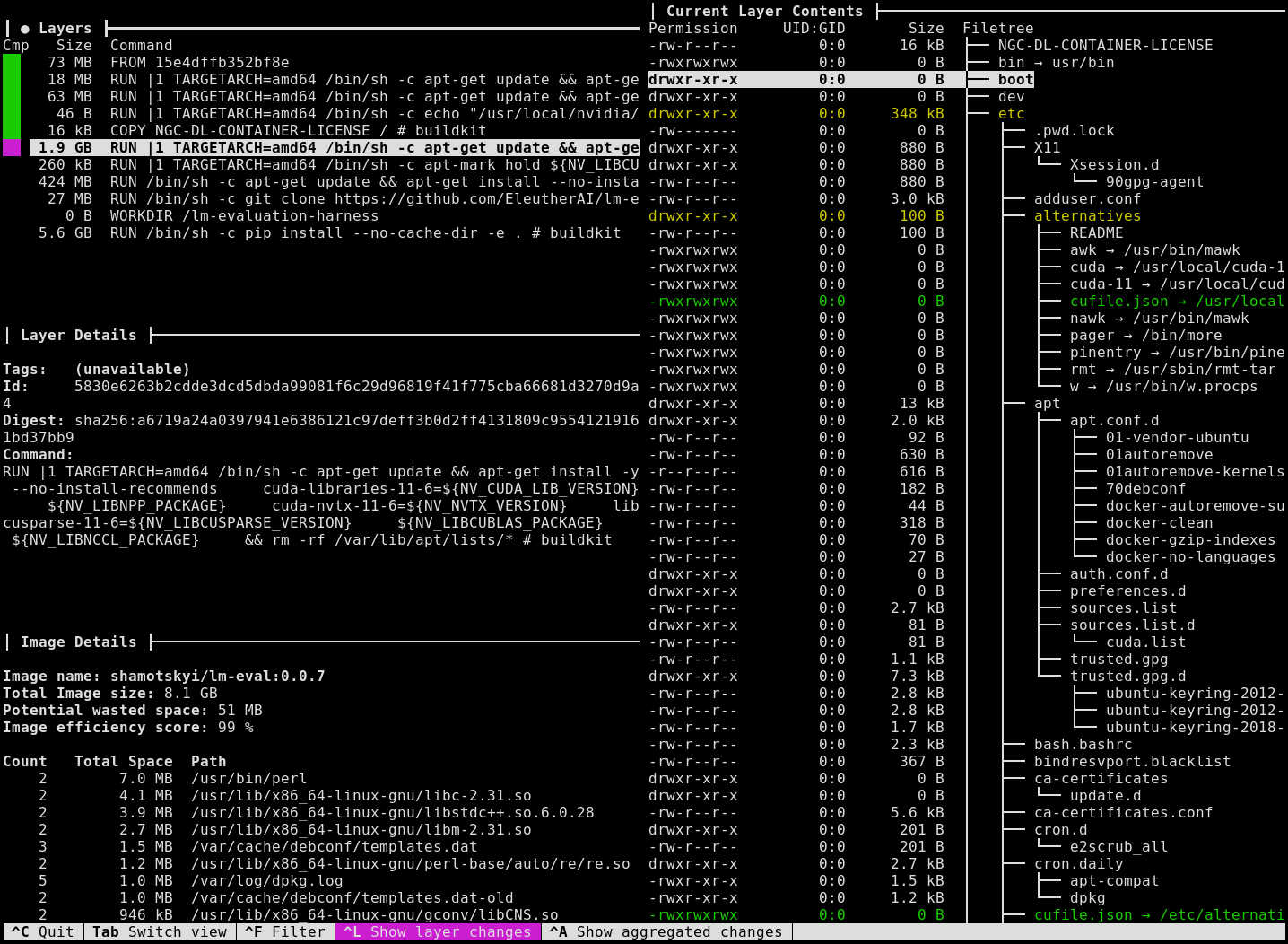
Dive for looking inside docker images
wagoodman/dive: A tool for exploring each layer in a docker image is cool.
dive myimage:tagtold me which line in my Dockerfile created a 5gb layerLooks really cool as well:
LLM playgrounds online
- Perplexity Labs <3
- NB changing the model takes effect only on refresh
- Whatever HF calls ‘spaces’, til learned about it, e.g.
- https://chat.lmsys.org/
- Not quite playgrounds
Poetry installing packages as -e ditable
pip install -e whatever poetry add -e whatever #e.g. poetry add -e git+https://github.com/EleutherAI/lm-evaluation-harnessSuch installed packages go into
./.venv/src/whatever, where they are editable.Nice.
- Perplexity Labs <3
-
Day 1855 (29 Jan 2024)
Writing evaluation code for my Masterarbeit
Previously:
- 231003-0015 My eval harness for masterarbeit notes (irrelevant now)
- 230928-1735 Other LM Benchmarks notes
- 231215-1740 Masterarbeit notes on running local models LM LLM
As before, lmentry code is a big inspiration.
Additionally:
- openai/evals: Evals is a framework for evaluating LLMs and LLM systems, and an open-source registry of benchmarks.
- EleutherAI/lm-evaluation-harness: A framework for few-shot evaluation of language models.
I didn’t want to write an eval harness, but somehow I find myself doing that — but instead of a benchmark thing, as one-time task, and worse than the existing ones. I wonder.
Again walking through existing evals
OpenAI evals
- evals/docs/build-eval.md at main · openai/evals
-
Each JSON object will represent one data point in your eval. The keys you need in the JSON object depend on the eval template. All templates expect an “input” key, which is the prompt, ideally specified in chat format (though strings are also supported). We recommend chat format even if you are evaluating non-chat models. If you are evaluating both chat and non-chat models, we handle the conversion between chat-formatted prompts and raw string prompts (see the conversion logic here).
- Do I have any reasons for not exporting my code bits to a jsonl file with standard keys?
-
- Example of an eval: evals/evals/registry/data/README.md at main · openai/evals
- Input in Chat format
- I love how
idealis a list of options, like [11,"11"].
- Many non-English evals! EVEN UKRAINIAN ONES evals/evals/registry/data at main · openai/evals
{"input": [{"role": "system", "content": "Ви отримаєте текст електронної петиції. Вам потрібно проаналізувати суть звернення та опираючись на законодавчу базу України та інші фактори відповісти чи підтримали би уряд цю петицію. Поясніть свій хід думок та висновок з позиції законодавства України."}, {"role": "user", "content": "Суть звернення: Повернути пільги на оплату електроенергії для населення, яке проживає у 30-кілометровій зоні атомних електростанцій. Відновити інші пільги населенню на оплату спожитої електричної енергії. Дата складання петиції - 2021 рік."}], "ideal": "Уряд не підтримав цю петицію, оскільки вважає, що питання надання пільг та субсидій на оплату комунальних послуг, в тому числі електроенергії, є повноваженням Кабінету Міністрів України а не уряду. Крім того, уряд вважає, що в державному бюджеті України на 2021 рік вже передбачено достатній обсяг коштів для компенсації витрат вразливим верствам населення, у тому числі для населення, що проживає в 30-кілометровій зоні атомних електростанцій."}-
Sample submission: Eval for Ukrainian electronic petitions by ziomio · Pull Request #1001 · openai/evals This is actually realistic!
-
Sample for multiple choice: https://github.com/openai/evals/blob/main/evals/registry/data/ukraine_eit/samples.jsonl
{ "input": [ { "role": "system", "content": "Ви розв'язуєте державний екзамен з української мови та літератури. Вкажіть літеру відповіді та текст відповіді дослівно, наприклад: Б. варіант відповіді" }, { "role": "user", "content": "Позначте словосполучення, у якому порушено граматичну норму на позначення часу:\nА. рівно о першій;\nБ. десять хвилин по шостій;\nВ. пів на десяту;\nГ. сім годин двадцять хвилин;\nД. за двадцять п’ята." } ], "ideal": "Г. сім годин двадцять хвилин;" } -
GEC! evals/evals/registry/data/ukraine_gec at main · openai/evals
-
- YAML with LMs, exact names and metadata for them: evals/evals/registry/completion_fns/langchain_llms.yaml at main · openai/evals
OK I’m definitely doing that.
And the example/parsing bit is important, since by default it’s often more verbose than I’d like:
EleutherAI Evaluation harness
-
lm-evaluation-harness/docs/new_task_guide.md at main · EleutherAI/lm-evaluation-harness
- At first sight: more complex and more flexible than eval
-
Supports things like multiple choice etc. out of the box!
- And generally has WAY more flexibility wrt. models, e.g. when to stop predicting
-
Datasets are HF datasets! (remote or local)
- And the task yamls describe how to transform the DS into LM input
- Mapping column names, answers etc.
doc_to_textis the model promptdoc_to_text: "Is the following statement hateful? Respond with either Yes or No. Statement: '{{text}}'"
doc_to_targetis either a stringyor the index of the correct label- … provided in
doc_to_choice, a list of stringsdoc_to_choice: "{{[ending0, ending1, ending2, ending3]}}"
- All can be given as functions!
- Multiple choice examples:
- SWAG
- SNLI has a longer multiple-shot prompt: lm-evaluation-harness/lm_eval/tasks/truthfulqa/truthfulqa_mc1.yaml
- TruthfulQA shows complexer data structures:
-
lm-evaluation-harness/lm_eval/tasks/truthfulqa/truthfulqa_mc1.yaml
doc_to_text: "{{support.lstrip()}}\nQuestion: {{question}}\nAnswer:" # This is the input portion of the prompt for this doc. It will have " {{choice}}" appended to it as target for each choice in answer_choices. doc_to_target: 3 # this contains the index into the answer choice list of the correct answer. doc_to_choice: "{{[distractor1, distractor2, distractor3, correct_answer]}}" -
(Awesome!) MMLU as used in the tutorial notebook:
- Mapping column names, answers etc.
- And the task yamls describe how to transform the DS into LM input
-
Cool tutorial on using the harness on a just-created task: lm-evaluation-harness/examples/lm-eval-overview.ipynb at main · EleutherAI/lm-evaluation-harness
- Shows two ways to do multiple-choice on the MMLU task
- comparing answers or log-likelyhood
- Shows two ways to do multiple-choice on the MMLU task
-
Interface (howto run) docs: lm-evaluation-harness/docs/interface.md at main · EleutherAI/lm-evaluation-harness
-
Decontamination: lm-evaluation-harness/docs/decontamination.md at main · EleutherAI/lm-evaluation-harness
- In: n-grams
- Out: measure how often these n-grams where present in dataset
-
For analyzing things, my tasks with my metadatas in them
--log-samplesin the main runner saves it on per-doc granularity (see interface)- source code: lm-evaluation-harness/lm_eval/evaluator.py at main · EleutherAI/lm-evaluation-harness
- One can write out the exact prompts to be used:
python write_out.py --tasks all_tasks --num_fewshot 5 --num_examples 10 --output_base_path /path/to/output/folder
-
It has even a cost estimate: lm-evaluation-harness/scripts/cost_estimate.py at main · EleutherAI/lm-evaluation-harness
-
Advanced usage tips shows how to pass
AutoModelargs to HF models -
Details on what went into the leaderboard can be seen as well:Open LLM Leaderboard - a Hugging Face Space by HuggingFaceH4
-
They support Zeno for visualizing stuff, and it’s cool: TruthfulQA | Zeno
Desiderata/TODOs for my case
Looking at the above:
- Main question: OpenAI Chat completion API VS Eleuther classic thing? + How do I integrate both?
- My datasets will live on HF hub, more or less consistent in their column names
- Datasets are a separate thing from what gets ‘fed’ to the eval
- I generate that during eval through templates?
SO:
-
=> Include semi-natively chat-completion-style instructions to my dataset dataclasses?
- I can test them here: Playground - OpenAI API
- I can test them here: Playground - OpenAI API
-
I love EleutherAI and Zeno and will be mainly using that! Instead of writing my own NIH bad eval package
-
Make all generators create dataclass-wizard-jsons AND flattened CSVs for all the tasks
-
CSV->HF in the eval package, together with the yamls for config
-
Oh look cbt · Datasets at Hugging Face
New eval-ua-tion package concept
- It will have:
- In: CSV? JSONs? w/ the dataset, that it will convert to HF and whatever
- It will have the yaml for tasks descriptions of the tasks to feed eval-lm
- it will have the eval-lm package, as well as the logic to run it (Dockerfile / Rancher pod YAML / ..) and save ti (??? as of yet)
- It may have some bits for analyzing/plotting the evaluation results
Relevant
-
Projects
- Vito Pepe Jaromir Völker / LLM Performance Testing · GitLab
- uses evals, lm-eval and another package as git submodules
- no readme but purpose is clear
- AUGMXNT/llm-experiments: Experiments w/ ChatGPT, LangChain, local LLMs
- Vito Pepe Jaromir Völker / LLM Performance Testing · GitLab
-
Dockers
- LLMPerformanceTest.Dockerfile · main · Vito Pepe Jaromir Völker / LLM Performance Testing · GitLab
- lm-evaluation-harness-de/Dockerfile at master · bjoernpl/lm-evaluation-harness-de
- much simpler for related project: bigcode-evaluation-harness/Dockerfile at main · bigcode-project/bigcode-evaluation-harness
-
llm-experiments/01-lm-eval.md at main · AUGMXNT/llm-experiments shows how to use lm-eval, and
-
. At these prices, running the above eval cost ~$90.77 (~4.5M tokens) and about 1h to run the tasks.
- LLM Worksheet - Google Sheets cool list of all existing models
-
-
TextSynth Server has a cool list of models, their sizes w/ diff quantizations, and scores on benchmarks
Interesting models
- HF
- mistralai/Mistral-7B-Instruct-v0.2
- didn’t have enough patience to wait for one instance
- TinyLlama/TinyLlama-1.1B-Chat-v1.0
- easy to run on CPU for testing
- mistralai/Mistral-7B-Instruct-v0.2
Running stuff
Created a docker w/ lm-eval, interactively playing with it
- cool params
--limit 1--device=cpuis a thing
Was able to run this on CPU!
root@88265fe7e6e4:/lm-evaluation-harness python3 -m lm_eval --model hf --model_args pretrained=TinyLlama/TinyLlama-1.1B-Chat-v1.0 --limit 1 --write_out --log_samples --output_path /tmp/outpt --tasks truthfulqa --device cpuGenerated this, took 19 minutes
: None, batch_size: 1 | Tasks |Version|Filter|n-shot| Metric | Value | |Stderr| |-----------------|-------|------|-----:|-----------|------:|---|------| |truthfulqa |N/A |none | 0|acc | 0.9251|± |N/A | | | |none | 0|bleu_max | 8.9138|± |N/A | | | |none | 0|bleu_acc | 0.0000|± |N/A | | | |none | 0|bleu_diff | 0.0000|± |N/A | | | |none | 0|rouge1_max |46.1538|± |N/A | | | |none | 0|rouge1_acc | 1.0000|± |N/A | | | |none | 0|rouge1_diff| 3.2967|± |N/A | | | |none | 0|rouge2_max |18.1818|± |N/A | | | |none | 0|rouge2_acc | 1.0000|± |N/A | | | |none | 0|rouge2_diff| 1.5152|± |N/A | | | |none | 0|rougeL_max |46.1538|± |N/A | | | |none | 0|rougeL_acc | 1.0000|± |N/A | | | |none | 0|rougeL_diff| 3.2967|± |N/A | | - truthfulqa_gen| 3|none | 0|bleu_max | 8.9138|± |N/A | | | |none | 0|bleu_acc | 0.0000|± |N/A | | | |none | 0|bleu_diff | 0.0000|± |N/A | | | |none | 0|rouge1_max |46.1538|± |N/A | | | |none | 0|rouge1_acc | 1.0000|± |N/A | | | |none | 0|rouge1_diff| 3.2967|± |N/A | | | |none | 0|rouge2_max |18.1818|± |N/A | | | |none | 0|rouge2_acc | 1.0000|± |N/A | | | |none | 0|rouge2_diff| 1.5152|± |N/A | | | |none | 0|rougeL_max |46.1538|± |N/A | | | |none | 0|rougeL_acc | 1.0000|± |N/A | | | |none | 0|rougeL_diff| 3.2967|± |N/A | | - truthfulqa_mc1| 2|none | 0|acc | 1.0000|± |N/A | | - truthfulqa_mc2| 2|none | 0|acc | 0.7752|± |N/A | | Groups |Version|Filter|n-shot| Metric | Value | |Stderr| |----------|-------|------|-----:|-----------|------:|---|------| |truthfulqa|N/A |none | 0|acc | 0.9251|± |N/A | | | |none | 0|bleu_max | 8.9138|± |N/A | | | |none | 0|bleu_acc | 0.0000|± |N/A | | | |none | 0|bleu_diff | 0.0000|± |N/A | | | |none | 0|rouge1_max |46.1538|± |N/A | | | |none | 0|rouge1_acc | 1.0000|± |N/A | | | |none | 0|rouge1_diff| 3.2967|± |N/A | | | |none | 0|rouge2_max |18.1818|± |N/A | | | |none | 0|rouge2_acc | 1.0000|± |N/A | | | |none | 0|rouge2_diff| 1.5152|± |N/A | | | |none | 0|rougeL_max |46.1538|± |N/A | | | |none | 0|rougeL_acc | 1.0000|± |N/A | | | |none | 0|rougeL_diff| 3.2967|± |N/A |pretrained__TinyLlama__TinyLlama-1.1B-Chat-v1.0_truthfulqa_gen.jsonl pretrained__TinyLlama__TinyLlama-1.1B-Chat-v1.0_truthfulqa_mc1.jsonl pretrained__TinyLlama__TinyLlama-1.1B-Chat-v1.0_truthfulqa_mc2.jsonl results.jsonresultscontains a lot, the other files contain the exact document IDs, the used prompts, etc. — perfect, it works!GoGame plan
-
I’ll try to avoid having installed the 5gb dependencies of lm-eval in the project
-
They will be installed in the Docker image
-
The project will contain only the yamls for my tasks
- They will be included with
--include_pathin the runner- Tried it, it works!
- You can allegedly also directly pass a yaml path to
--tasks
- They will be included with
-
Unsolved
- Where to save results?
- Rancher space thing, whatever it’s called?
- scp them somewhere?
First custom task
Had a dataset on HF, used it:
task: pravda dataset_path: shamotskyi/ukr_pravda_2y dataset_name: null # output_type: multiple_choice training_split: null validation_split: null test_split: train doc_to_text: "Predict a title for the following news: {{eng_text}}" doc_to_target: "{{eng_title}}" # doc_to_choice: "{{choices.text}}" # should_decontaminate: true # doc_to_decontamination_query: question_stem metric_list: - metric: bleu aggregation: mean higher_is_better: true metadata: version: 1.0Changed metric to bleu, and used my rows.
Problem: some of the rows are null for the English text.
datasets.exceptions.DatasetGenerationCastError: An error occurred while generating the dataset All the data files must have the same columns, but at some point there are 6 new columns (id, lang, kind, uri, date, domain) and 20 missing columns (rus_title, eng_text, tags, ukr_tags_full, rus_uri, rus_tags, ukr_text, date_published, eng_tags, rus_text, eng_title, ukr_author_name, ukr_uri, eng_uri, eng_tags_full, ukr_title, rus_author_name, eng_author_name, rus_tags_full, ukr_tags).OK then :( all have to be equal
Using a local dataset
Local dataset or model path support · Issue #1224 · EleutherAI/lm-evaluation-harness showed how to use a local HF dataset (not json as shown in the tutorial):
task: lmentry dataset_path: arrow dataset_kwargs: data_files: train: /resources/ds/dataset/hf_WordsAlphabetOrder/data-00000-of-00001.arrow # dataset_name: null # output_type: multiple_choice training_split: null validation_split: null test_split: train doc_to_text: "{{question}}" doc_to_target: "{{correctAnswer}}" metric_list: - metric: bleu # aggregation: mean # higher_is_better: true metadata: version: 1.0
THIS GAVE ME THE FIRST NON-1.0 SCORE! I just had to use more test instances
root@lm-eval-sh:/lm-evaluation-harness# python3 -m lm_eval --model hf --model_args pretrained=TinyLlama/TinyLlama-1.1B-Chat-v1.0 --limit 520 --write_out --log_samples --output_path /tmp/Output --tasks lmentry --include_path /resources --verbosity DEBUG --show_configokay!
hf (pretrained=mistralai/Mistral-7B-Instruct-v0.2), gen_kwargs: (None), limit: 20000.0, num_fewshot: None, batch_size: 1 | Tasks |Version|Filter|n-shot|Metric|Value| |Stderr| |-------|------:|------|-----:|------|----:|---|-----:| |lmentry| 1|none | 0|acc |0.485|± |0.0354| hf (pretrained=mistralai/Mistral-7B-Instruct-v0.2), gen_kwargs: (None), limit: 20000.0, num_fewshot: 2, batch_size: 1 | Tasks |Version|Filter|n-shot|Metric|Value| |Stderr| |-------|------:|------|-----:|------|----:|---|-----:| |lmentry| 1|none | 2|acc |0.685|± |0.0329| hf (pretrained=mistralai/Mistral-7B-Instruct-v0.2), gen_kwargs: (None), limit: 20000.0, num_fewshot: 10, batch_size: 1 | Tasks |Version|Filter|n-shot|Metric|Value| |Stderr| |-------|------:|------|-----:|------|----:|---|-----:| |lmentry| 1|none | 10|acc | 0.78|± |0.0294|OK! Increasing num_fewshot on that exact same test set predictably increases scores. OK, it all starts to make sense <3
So, fazit:
- accuracy version breaks
- multi-choice one works more or less predictably, but <0.5 with zero-shot?
Either way goal was to run an eval that at least runs, mission accomplished.
Onwards
non-English multichoice example:
- lm-evaluation-harness/lm_eval/tasks/xstorycloze/default_ru.yaml at big-refactor · EleutherAI/lm-evaluation-harness
- Includes lm-evaluation-harness/lm_eval/tasks/xstorycloze/default_ar.yaml at big-refactor · EleutherAI/lm-evaluation-harness
- juletxara/xstory_cloze · Datasets at Hugging Face
- It contains a train split as well. Most seem to.
I now understand why non-mc tasks failed with
accmetric.task: lmentry_low dataset_path: arrow dataset_kwargs: data_files: train: /datasets/hf_LOWTask/data-00000-of-00001.arrow # dataset_name: null #output_type: multiple_choice training_split: null validation_split: null test_split: train doc_to_text: "{{question}}" doc_to_target: "{{correctAnswer}}" #doc_to_choice: "{{[additionalMetadata_option_0, additionalMetadata_option_1]}}" # doc_to_choice: "{{['yes', 'no']}}" # should_decontaminate: true # doc_to_decontamination_query: question_stem metric_list: - metric: exact_match aggregation: mean higher_is_better: true ignore_case: true ignore_punctuation: true metadata: version: 1.0python3 -m lm_eval \ --model hf \ --model_args pretrained=mistralai/Mistral-7B-v0.1 \ --limit 100 \ --write_out \ --log_samples \ --output_path /MOutput \ --tasks low \ --device cuda \ --verbosity DEBUG \ --include_path /resources \ --show_config \ --num_fewshot 2Useful bits for tasks
metric_list: - metric: exact_match aggregation: mean higher_is_better: true ignore_case: true ignore_punctuation: trueI can do
doc_to_text: "{{system_prompts[0]}}. {{question}}"Knowing when to stop
"arguments": [ [ "Ви розв'язуєте екзамен з української мови. Вкажіть правильну відповідь одним словом, без лапок. Наприклад: \\n Питання: В слові \"герметизація\" яка літера третя?\\n Відповідь: р. Яка літера в слові \"собака\" перша?", { "until": [ "\n\n" ], "do_sample": false } ] ], "resps": [ [ "\\n Відповідь: с. Яка літера в слові \"політика\" четверта?\\n Відповідь: т. Яка літера в слові \"політика\" п'ята?\\n Відповідь: к. Яка літера в слові \"політика\" шоста?\\n Відповідь: і. Яка літера в слові \"політика\" сьома?\\n Відповідь: т. Яка літера в слові \"політика\" восьма?\\n Відповідь: к. Яка літера в слові \"політика\" дев'ята?\\n Відповідь: а. Яка літера в слові \"політика\" десята?\\n Відповідь: л. Яка літера в слові \"політика\" одинадцята?\\n Відповідь: і. Яка літера в слові \"політика\" дванадцята?\\n Відпов" ] ],is important it seems, haha. And editing my own examples is important as well if I manually inject system prompts instead of n_shot:
"target": "с", "arguments": [ [ "Ви розв'язуєте екзамен з української мови. Вкажіть правильну відповідь одним словом, без лапок. Наприклад: \\n Питання: В слові \"герметизація\" яка літера третя?\\n Відповідь: р. В слові \"собака\" на першому місці знаходиться літера ...", { "until": [ "\n\n" ], "do_sample": false } ]-
Mistral Instruct is better than vanilla for low taks
-
lm-evaluation-harness/docs/task_guide.md at main · EleutherAI/lm-evaluation-harness has info about the FULL configuration!
output_type: generate_until target_delimiter: "" generation_kwargs: until: - "\n\n" - "\n" do_sample: false temperature: 0.0 target_delimiter: " " metric_list: - metric: exact_match aggregation: mean higher_is_better: true ignore_case: true ignore_punctuation: true filter_list: - name: "get-answer" filter: - function: "regex" regex_pattern: "The answer is (\\-?[0-9\\.\\,]+)" - function: "take_first"filter_list: - name: remove_whitespace filter: - function: remove_whitespace - function: take_first(from mgsm/en_cot/cot_yaml)
ag generation -A 8helps find examplesI can’t find any good documentation on many of the params used.
- About the results of WizardMath on GSM8K · Issue #1274 · EleutherAI/lm-evaluation-harness
-
For the base gsm8k task, we match the format used by the original GSM8k publication, where the format is Q: <question> \nA: <reasoning chain> #### <numeric answer> and are strict about only extracting an answer from the format #### <numeric answer>. Because models don’t know to output this format, they do not perform well 0-shot on it, but can do so few-shot.
-
So many things to learn from issues instead of documentation: always get acc,acc_norm, perplexity =1 on triviaqa task based on llama2 model · Issue 1239 · EleutherAI/lm-evaluation-harness
-
TODO why do different tasks use different parameters for things like when to stop generating?
-
lm-evaluation-harness/lm_eval/tasks/gsm8k/gsm8k-cot.yaml at 25a15379676c8a2fa0b93ca9c4742b156e1fec39 · EleutherAI/lm-evaluation-harness cool example of evaluating a chain of thought prompt where “A: $expanation. The answer is XXX.” is part of the conditioning, then the answer is gotten via regex (
regex_pattern: "The answer is (\\-?[0-9\\.\\,]+).") -
I should change generate_until to include whatever QA words I use as example.
This worldlengthcomparison task gets a whopping 0.62 w/ mistral7b-notistruct using the same formulation as the others:
task: wlc_nomulti group: lmentry dataset_path: arrow dataset_kwargs: data_files: train: /datasets/hf_WordLengthComparison/train/data-00000-of-00001.arrow test: /datasets/hf_WordLengthComparison/test/data-00000-of-00001.arrow # dataset_name: null #output_type: generate_until #num_fewshot: 3 generation_kwargs: until: - "\n\n" - "\n" - "." # max_length: 40 training_split: null validation_split: null test_split: train fewshot_split: test doc_to_text: "{{question}}" doc_to_target: "{{correctAnswer}}" #doc_to_choice: "{{[additionalMetadata_option_0, additionalMetadata_option_1]}}" # doc_to_choice: "{{['yes', 'no']}}" # should_decontaminate: true # doc_to_decontamination_query: question_stem metric_list: - metric: exact_match aggregation: mean higher_is_better: true ignore_case: true ignore_punctuation: true metadata: version: 1.0-
I get really close results for both wlc tasks!
-
HA! Lmentry explicitly lists base patterns: lmentry/lmentry/scorers/first_letter_scorer.py at main · aviaefrat/lmentry
starts = "(starts|begins)" base_patterns = [ rf"The first letter is {answer}", rf"The first letter {of} {word} is {answer}", rf"{answer} is the first letter {of} {word}", rf"{word} {starts} with {answer}", rf"The letter that {word} {starts} with is {answer}", rf"{answer} is the starting letter {of} {word}", rf"{word}: {answer}", rf"First letter: {answer}", ]Zeno
export ZENO_API_KEY=zen_xxxx root@lm-eval-sh:/lm-evaluation-harness# pip install zeno-client==0.1.9 root@lm-eval-sh:/lm-evaluation-harness# PYTHONPATH=. python3 scripts/zeno_visualize.py --data_path=/Output --project_name "test"More edge cases
again, this would need to be filtered out. From prompts definitely, they need spaces. But also generate_until.
"arguments": [ [ "В слові \"їжа\" під номером один знаходиться літера ... ї\n\nВ слові \"синхрофазотрон\" під номером дев'ять знаходиться літера ...з\n\nЯка літера в слові \"ліжко\" перша? л\n\nЯка літера в слові \"їжа\" остання?", { "until": [ "\n\n" ], "do_sample": false } ] ], "resps": [ [ "... я" ] ], "filtered_resps": [ "... я" ], "bleu": [ "а", "... я" ]KRUK
robinhad/kruk: Ukrainian instruction-tuned language models and datasets oh damn
Filters
lm-evaluation-harness/lm_eval/tasks/bbh/cot_zeroshot/_cot_zeroshot_template_yaml at e0eda4d3ffa10e5f65e0976161cd134bec61983a · EleutherAI/lm-evaluation-harness is a neat example of filter:
filter_list: - name: "get-answer" filter: - function: "regex" regex_pattern: "((?<=The answer is )(.*)(?=.)|(?<=the answer is )(.*)(?=.)|(?<=The answer: )(.*)(?=.)|(?<=The final answer: )(.*)(?=.))" - function: "take_first"